
SELECT
CONCAT('ALTER TABLE `',any_value(TABLE_NAME),'` ', 'ADD ',
IF(any_value(NON_UNIQUE) = 1,
CASE UPPER(any_value(INDEX_TYPE))
WHEN 'FULLTEXT' THEN 'FULLTEXT INDEX'
WHEN 'SPATIAL' THEN 'SPATIAL INDEX'
ELSE CONCAT('INDEX `',
any_value(INDEX_NAME),
'` USING ',
any_value(INDEX_TYPE)
)
END,
IF(UPPER(any_value(INDEX_NAME)) = 'PRIMARY',
CONCAT('PRIMARY KEY USING ',
any_value(INDEX_TYPE)
),
CONCAT('UNIQUE INDEX `',
any_value(INDEX_NAME),
'` USING ',
any_value(INDEX_TYPE)
)
)
),'(', GROUP_CONCAT(DISTINCT CONCAT('`', any_value(COLUMN_NAME), '`') ORDER BY SEQ_IN_INDEX ASC SEPARATOR ', '), ');') AS 'Show_Add_Indexes'
FROM information_schema.STATISTICS
where COLUMN_NAME<>'id'
GROUP BY TABLE_NAME, INDEX_NAME
ORDER BY TABLE_NAME ASC, INDEX_NAME ASC;mysql 导入数据太慢,来教你实用干货 原创
导出 或 导入数据,尽可能的使用 MySQL 自带命令工具 ,不要使用一些图形化的工具 (Navicat…)。因为 MySQL 命令行工具至少要比图形化工具快 2 倍 。
命令工具行方式:
导出整个实例 mysqldump -u 用户名 -p 密码 --all-databases > all_database.sql
导出指定库 mysqldump -u 用户名 -p 密码 --databases testdb > testdb.sql
导出指定表 mysqldump -u 用户名 -p 密码 testdb test_tb > test_tb.sql
导入指定 SQL 文件 (指定导入 testdb 库中) mysql -u 用户名 -p 密码 testdb < testdb.sql
小技巧 - 方案二 修改参数方式:
在 MySQL 中,有这么一对参数很有意思,分别是:
“ innodb_flush_log_at_trx_commit ”
与
“ sync_binlog ”
安全性考虑,这个参数默认是 1 ,为了快速导入 sql 数据,可临时修改默认参数值。
参数一: innodb_flush_log_at_trx_commit 默认值为 1,可设置为 0、1、2
innodb_flush_log_at_trx_commit 设置为 0,log buffer 将每秒一次地写入 log file 中,并且 log file 的 flush(刷到磁盘)操作同时进行.该模式下,在事务提交的时候,不会主动触发写入磁盘的操作。
innodb_flush_log_at_trx_commit 设置为 1,每次事务提交时 MySQL 都会把 log buffer 的数据写入 log file,并且 flush(刷到磁盘)中去。
innodb_flush_log_at_trx_commit 设置为 2,每次事务提交时 MySQL 都会把 log buffer 的数据写入 log file.但是 flush(刷到磁盘)操作并不会同时进行。该模式下,MySQL 会每秒执行一次 flush(刷到磁盘)操作。
参数二: sync_binlog 默认值为 1,可设置为[0,N)
当 sync_binlog =0,像操作系统刷其他文件的机制一样,MySQL 不会同步到磁盘中去而是依赖操作系统来刷新 binary log。
当 sync_binlog =N (N>0) ,MySQL 在每写 N 次 二进制日志 binary log 时,会使用 fdatasync()函数将它的写二进制日志 binary log 同步到磁盘中去。
注意:这两个参数可以在线修改,若想快速导入,可按照以下命令行
1.进入 MySQL 命令行 临时修改这两个参数 set global innodb_flush_log_at_trx_commit = 2;
set global sync_binlog = 2000;
2.执行 SQL 脚本导入 mysql -uroot -pxxxxxx testdb < testdb.sql
docker exec -i mysql sh -c "exec mysql -uroot -proot -v" < xxx.sql
mysql -uroot -p -v -e "source /xxx.sql";
3.导入完成 再把参数改回来 set global innodb_flush_log_at_trx_commit = 1;
set global sync_binlog = 1;
ALTER TABLE my_table DISABLE KEYS; -- 禁用所有索引 -- 执行批量插入... ALTER TABLE my_table ENABLE KEYS; -- 重新启用索引并重建
分库分表
shardingsphere
由三款开源的分布式数据库中间件 sharding-jdbc、sharding-proxy 和 sharding-sidecar 所构成
分片规则配置
jdbc规范重写
sql解析
sql改写
sql路由
sql执行
结果归并零填充
CREATE TABLE `user` (
`id` int(4) unsigned zerofill NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`id`)
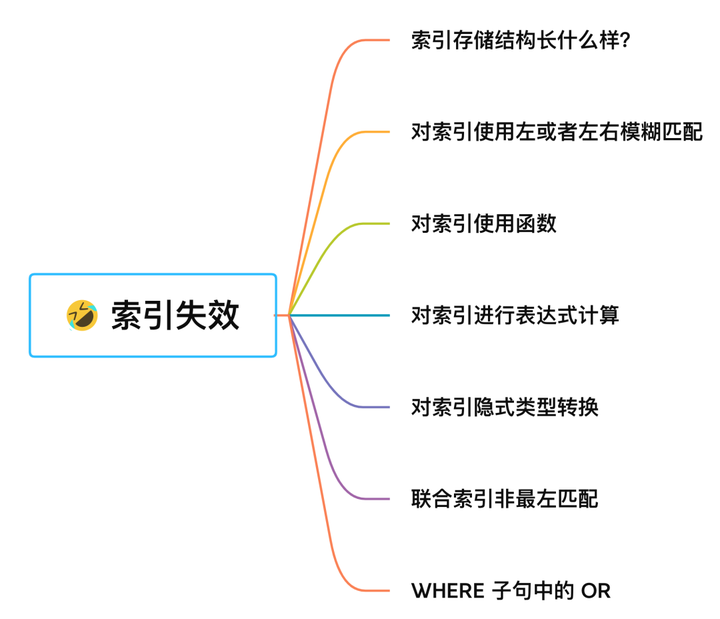
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4;索引失效
explain

事务传播
REQUIRED:支持当前事务,如果当前不存在则新开启一个事务(默认配置)
SUPPORTS:支持当前事务,如果当前不存在事务则以非事务方式执行
MANDATORY:支持当前事务,如果当前不存在事务则抛出异常
REQUIRES_NEW:创建一个新事务,如果当前已存在事务则挂起当前事务
NOT_SUPPORTED:以非事务方式执行,如果当前已存在事务则挂起当前事务
NEVER:以非事务方式执行,如果当前已存在事务则抛出异常
NESTED:如果当前存在事务,则在嵌套事务中执行,否则开启一个新事务replace
sql
UPDATE xxxx SET resid=REPLACE(xx,'1','2'),roleid=replace(xxx,'1','2');随机
SELECT
*
FROM
( SELECT ( @ROW := @ROW + 1 ) AS rownum,xxx.* FROM xxx xxx,( SELECT @ROW := 0 ) AS t ) AS temp
WITH RECURSIVE sequence AS (
SELECT 1 AS num
UNION ALL
SELECT num + 1 FROM sequence WHERE num < 10
)
SELECT * FROM sequence;
select tt.row from
(
SELECT cast( concat(t.0,t2.0,t3.0) + 1 As UNSIGNED) as 'row' FROM
(select 0 union select 1 union select 2 union select 3 union select 4 union select 5 union select 6 union select 7 union select 8 union select 9) t,
(select 0 union select 1 union select 2 union select 3 union select 4 union select 5 union select 6 union select 7 union select 8 union select 9) t2,
(select 0 union select 1 union select 2 union select 3 union select 4 union select 5 union select 6 union select 7 union select 8 union select 9) t3
) tt
order by tt.rowpassword
sql
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY 'xxxx';
FLUSH PRIVILEGES;mybatis 变量
WHERE xxx.`status` =${@com.test.xxxx@YES.getCode()}on where 加条件区别
在使用 left join 时,on 和 where 条件的区别如下:
1、 on 条件是在生成临时表时使用的条件,它不管 on 中的条件是否为真,都会返回左边表中的记录。
2、where 条件是在临时表生成好后,再对临时表进行过滤的条件。这时已经没有 left join 的含义(必须返回左边表的记录)了,条件不为真的就全部过滤掉。
放 on 里是左连接前过滤,放外边 where 里是对结果进行过滤。先和后的问题
grant all privileges on . to 'root'@'%' identified by '123456' with grant option; mysql 8.0以上
CREATE USER sd@'%' ; -- 创建用户 ALTER USER root@'%' IDENTIFIED BY '123456'; -- 指定密码 GRANT ALL PRIVILEGES ON . TO root@'%' WITH GRANT OPTION; -- 授权
jdbc批处理
rewriteBatched-Statements=true&useServerPrepStmts=false高阶函数
窗口函数: 对分组统计结果中的每一条记录进行计算
WITH 子句是 MySQL 中的一种 SQL 结构,又称为 Common Table Expression (CTE)
SELECT REGEXP_REPLACE('[Hello World]', '\\[|\\]', '') AS result;
ROW_NUMBER( ) OVER ()
RANK() OVER()
PARTITION BY
order by field()
lag (last value)
lead (lead value)select count 效率
count(*) ≈ count(常量) > count(id) > count(字段)
数据库中表
SELECT
t.table_name AS table_name,
GROUP_CONCAT( c.column_name ORDER BY c.ordinal_position ASC ) AS column_name
FROM
information_schema.`tables` t
LEFT JOIN information_schema.`columns` c ON t.table_name = c.table_name
AND t.table_schema = c.TABLE_SCHEMA
WHERE
t.table_schema = 'xxx'
GROUP BY
t.table_name;
SELECT
table_schema,
table_name,
update_time,
table_rows
FROM
information_schema.`TABLES`
WHERE
table_type = 'BASE TABLE'
AND ENGINE = 'InnoDB'
ORDER BY
UPDATE_TIME DESC,
table_rows DESC
LIMIT 10;树结构的递归
WITH RECURSIVE cte AS (
SELECT id, pid, res_name FROM resource WHERE pid IS NULL
UNION ALL
SELECT t.id, t.pid, t.res_name FROM resource t JOIN cte c ON t.pid = c.id )
SELECT * FROM cte;
select * from (
SELECT t1.id, ifnull(t1.pid,''), t1.res_name FROM resource t1 WHERE t1.pid IS NULL
union all
SELECT t1.id, ifnull(t1.pid,''), t1.res_name FROM resource t1 JOIN resource t2 ON t1.pid=t2.id) as t order by t.id asc变量
SET @myVar = 100;
SELECT @myVar;ognl
ognl Object-Graph Navigation Language 对象导航图语言
mybatis
动态sql
批量操作
高级查询
- 调用类的静态方法 :@class@method(args)
SELECT * FROM USER WHERE mobile_phone = '${@xxx.xxxx@xxx(xxx)}'
2、 mybatis的if 标签中,test 也是可以调用自定义的方法的
olap oltp
oltp 联机事务处理
olap 联机分析处理
sql
DQL:数据查询语言,用于对数据进行查询,如select
DML:数据操作语言,对数据进行增加、修改、删除,如insert、update、delete。
TPL: 事务处理语言,对事务进行处理,包括begin transaction、commit、rollback。
DCL:数据控制语言,进行授权与权限回收,如grant、revoke
DDL:数据定义语言,进行数据库、表的管理等,如create、drop
mysql json
select JSON_EXTRACT(xxx, '$**.settings') from xxx where xxx REGEXP 'setting' ;
where JSON_CONTAINS_PATH(xxxx,'one','$.aa')>0
->:获取JSON文档的指定成员。
->>:获取JSON文档的指定成员,并将其作为无引号的字符串返回。
JSON_EXTRACT(json_doc, path):提取JSON文档中的数据。
JSON_SET(json_doc, path, val):更新JSON文档中的数据。
JSON_INSERT(json_doc, path, val):向JSON文档中插入数据,如果路径已存在,则不进行任何操作。
JSON_REPLACE(json_doc, path, val):替换JSON文档中的数据。
JSON_REMOVE(json_doc, path):从JSON文档中删除数据。删除重复项
delete from xxxxx
where id in (
select id from (
SELECT
max( id ) AS id
FROM
`xxxxxx` epid
GROUP BY
epid.create_time,
epid.xxxxxx
HAVING
(
count( epid.xxxxxx))> 1 ) as t )递归树结构
递归查找父级
SELECT
t2.id,
lvl as `level`
FROM
(
SELECT
@r AS _id,
( SELECT @r := parent_id FROM sys_org WHERE id = _id ) AS parent_id,
@l := @l + 1 AS lvl
FROM
( SELECT @r := 21, @l := 0 ) vars,
sys_org
) t1
JOIN sys_org t2 ON t1._id = t2.id;
递归查找子级
SELECT
t.id
FROM
( SELECT * FROM sys_org WHERE (parent_id IS NOT NULL and parent_id>0) ) t
WHERE
FIND_IN_SET( parent_id, @pid ) > 0
AND @pid := CONCAT(
@pid,
',',
id)select insert
set @create_id=577;
set @create_time=now();
SELECT
GROUP_CONCAT(
'insert into gc_project(`xx`,`xxx`,`xx`,`deleted`,`create_time`,`create_id`,`update_time`,`update_id`) VALUES (',
CONCAT_WS(
',',
CONCAT( "'", proj_num, "'" ),
CONCAT( "'", `name`, "'" ),
CONCAT( "'", 'XHYL', "'" ),
0,
CONCAT( "'", @create_time, "'" ),
CONCAT( "'", @create_id, "'" ) ,
CONCAT( "'", @create_time, "'" ),
CONCAT( "'", @create_id, "'" )
)
,');' SEPARATOR '') as `sql`
FROM
xxxx
WHERE
flag = 1
GROUP BY idgroup concat 长度限制
my.cnf
[mysqld]
group_concat_max_len = new_max_len
临时解决 SET SESSION group_concat_max_len = 1000000;锁
Next-Key Lock(临键锁)行级锁
Next-Key Lock = Record Lock(行锁) + Gap Lock(间隙锁) 防止幻读(Phantom Read)
Next-Key Lock 是 InnoDB 在可重复读(RR)隔离级别下,对当前读加的“行 + 间隙”锁,既锁住已有记录,也锁住可能插入新记录的位置,从而防止幻读。
更新事务的核心是两阶段提交 + redo log 保证数据不丢,行级锁保证并发安全,所有更新都是事务内操作,要么全成功要么全回滚
按操作属性分
共享锁 S Lock 多个事务读取同一行数据,互不影响
排他锁 X Lock 一个事务更新数据,其他不能读也不可以更新
按作用范围分
全局锁
表锁
行级锁
InnoDB行级锁的算法(实现方式)
记录锁
间歇锁
临键锁
两段锁
事务开始时获取锁,结束时释放锁## Binlog两阶段提交过程
redo log prepare->bin log write->redo log commitbinlog、redolog和undolog区别
适用场景:binlog 用于全存储引擎的数据备份、恢复与复制;redolog 和 undolog 仅用于 InnoDB 引擎,前者保障崩溃恢复和持久化,后者用于事务回滚及 MVCC。
记录内容:binlog 记 DDL、DML 语句;redolog 记事务数据改动;undolog 记事务修改前的数据。
实现机制:binlog 按指定格式记录,有语句和行格式;redolog 循环写,崩溃时重执行记录;undolog 反向执行记录来撤销修改。
原子性:通过undo log保证,如果事务失败或需要回滚,undo日志中的信息可以用来撤销事务的所有更改,将数据库状态恢复到事务开始之前。
一致性:InnoDB通过约束、触发器和MVCC(多版本并发控制)等机制来维护一致性。
隔离性:InnoDB通过锁机制(如行级锁和表级锁)和MVCC来实现事务的隔离性。
持久性:InnoDB通过redo log来保证事务的持久性。事务提交时,所有的修改操作记录在redo日志中,并在必要时将这些更改应用到数据库中以恢复事务的状态
binlog(Binary Log)是MySQL Server层的逻辑日志,以二进制形式记录所有对数据库的更改操作(DDL和DML语句,不包括SELECT)
主从复制:主库将binlog发送给从库,从库重放日志实现数据同步
时间点恢复:通过mysqlbinlog工具回放binlog,将数据库恢复到某个时间点
审计:记录所有数据库变更,用于安全审计
redo log
崩溃恢复、保证持久性
redo log buffer:内存中的日志缓冲区
redo log file:磁盘上的日志文件(固定大小,循环使用)
innodb_flush_log_at_trx_commit=1
undo log
事务回滚:当事务执行失败或执行ROLLBACK时,利用undo log将数据恢复到修改前的状态
MVCC(多版本并发控制)Multi-Version Concurrency Control, MVCC :为InnoDB实现可重复读隔离级别提供支持,让读操作不阻塞写操作
ACID靠什么保证的呢?
以MySQL为例:
A原子性由undo log日志保证,它记录了需要回滚的日志信息,事务回滚时撤销已经执行成功的sql
C一致性一般由代码层面来保证
I隔离性由MVCC+锁来保证
D持久性由内存+redo log来保证,mysql修改数据同时在内存和redo log记录这次操作,事务提交的时候通过redo log刷盘,宕机的时候可以从redo log恢复myql隐藏字段
mysql都会默认添加3个隐藏列字段。
DB_TRX_ID :6 byte,最近修改( 修改/插入 )事务ID,记录创建这条记录/最后一次修改该记录的事务ID
DB_ROLL_PTR : 7 byte,回滚指针,指向这条记录的上一个版本(简单理解成,指向历史版本就行,这些数据一般在 undo log 中)
DB_ROW_ID : 6 byte,隐含的自增ID(隐藏主键),如果数据表没有主键, InnoDB 会自动以DB_ROW_ID 产生一个聚簇索引
补充:实际还有一个删除flag隐藏字段, 既记录被更新或删除并不代表真的删除,而是删除flag变了
MySQL(InnoDB)中,多表JOIN默认采用Nested Loop Join:从第一张表(驱动表)取出一行,然后循环去下一张表匹配;重复这个过程直到所有表关联完
自适应哈希索引的工作原理:
InnoDB会自动监测表的访问模式。 当它检测到某些页面被频繁访问时,会将这些页面的索引条目创建为哈希索引。 这样可以在后续查询中通过哈希表快速定位这些条目,减少查找时间。